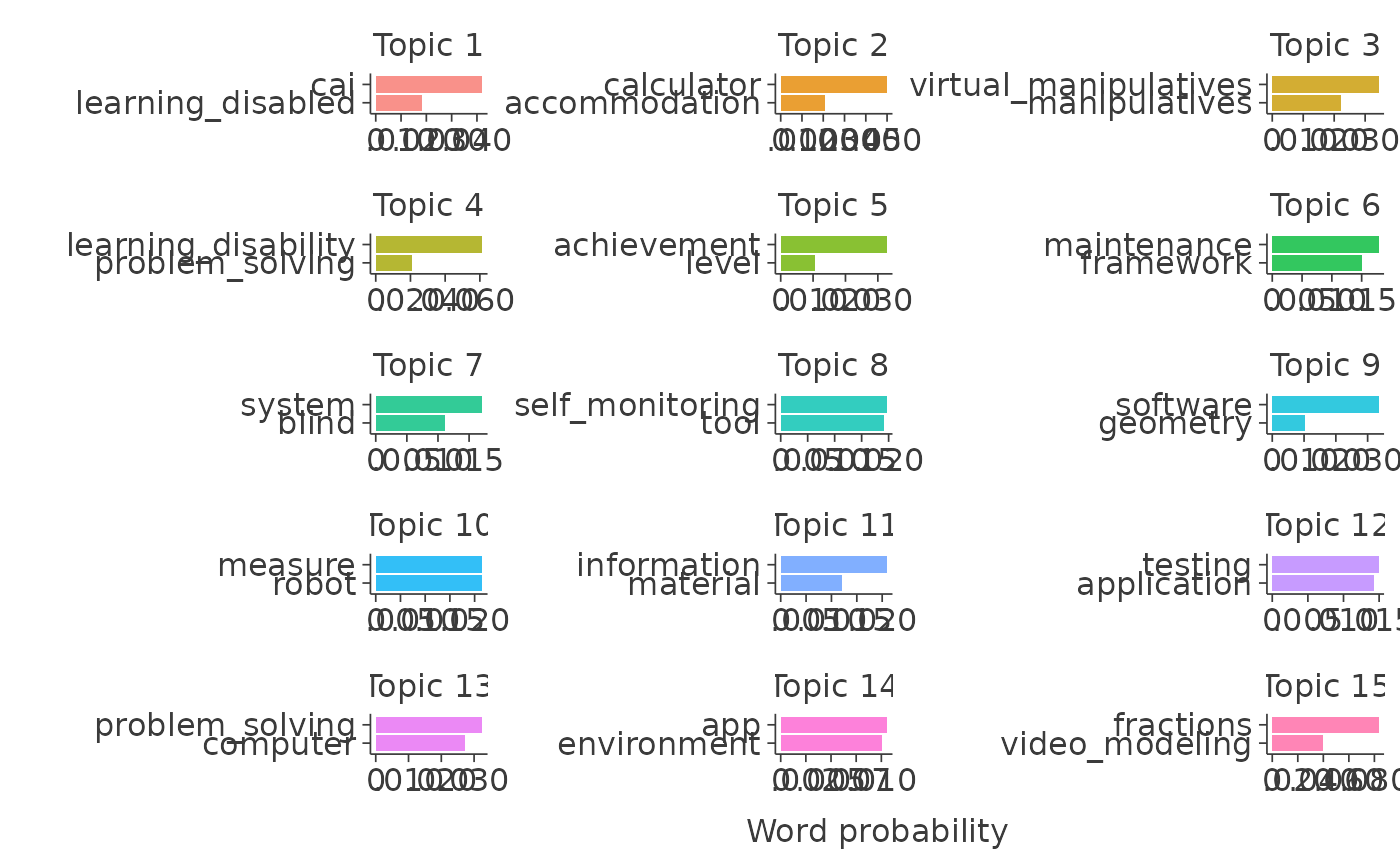
Plot per-term per-topic probabilities with highest word probabilities.
Arguments
- data
A tidy data frame that includes per-term per-topic probabilities (beta).
- ncol
A number of columns in the facet plot.
- topic_names
(Labeled) topic names
- ...
Further arguments passed to
dplyr::group_by.
Value
A ggplot object output from stm::stm, tidytext::tidy, and ggplot2::ggplot.
The result is a ggplot object representing the topic-term plot.
Examples
suppressWarnings({
if(requireNamespace("quanteda", "tidytext")){
dfm <- SpecialEduTech %>%
preprocess_texts(text_field = "abstract") %>%
quanteda::dfm()
data <- tidytext::tidy(stm_15, document_names = rownames(dfm), log = FALSE)
data %>% examine_top_terms(top_n = 2) %>%
plot_topic_term(ncol = 3)
}
})